Info
openproblems_
Tasic et al. (2016)
1.91 GiB
02-02-2024
14249 cells × 34617 genes
openproblems_
Tasic et al. (2016)
1.91 GiB
02-02-2024
14249 cells × 34617 genes
CREATED
02-02-2024
DIMENSIONS
14249 × 34617
A murine brain atlas with adjacent cell types as assumed benchmark truth, inferred from deconvolution proportion correlations using matching 10x Visium slides (see Dimitrov et al., 2022).
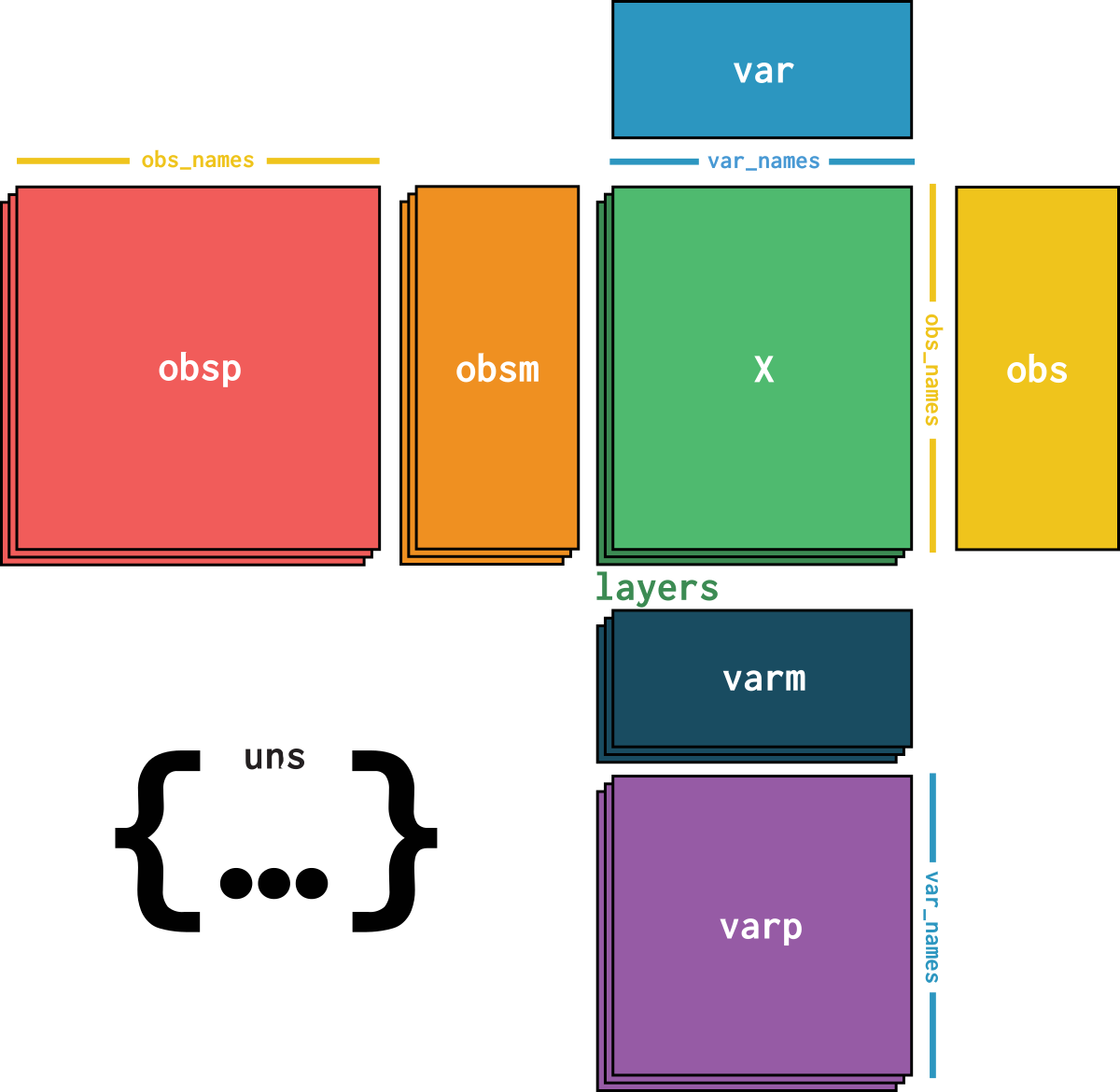
dataset is an AnnData object with n_obs × n_vars = 14249 × 34617 with slots:
cell_type, size_factorsfeature_name, hvg, hvg_scoreknn_connectivities, knn_distancesX_pcapca_loadingscounts, normalizeddataset_description, dataset_id, dataset_name, dataset_organism, dataset_reference, dataset_summary, dataset_url, knn, normalization_id, pca_variance| Name | Description | Type | Data type | Size |
|---|---|---|---|---|
| obs | ||||
cell_
|
Classification of the cell type based on its characteristics and function within the tissue or organism. |
vector
|
category
|
14249 |
size_
|
The size factors created by the normalisation method, if any. |
vector
|
float32
|
14249 |
| var | ||||
feature_
|
A human-readable name for the feature, usually a gene symbol. |
vector
|
object
|
34617 |
hvg
|
Whether or not the feature is considered to be a ‘highly variable gene’ |
vector
|
bool
|
34617 |
hvg_
|
A ranking of the features by hvg. |
vector
|
float64
|
34617 |
| obsp | ||||
knn_
|
K nearest neighbors connectivities matrix. |
sparsematrix
|
float32
|
14249 × 14249 |
knn_
|
K nearest neighbors distance matrix. |
sparsematrix
|
float64
|
14249 × 14249 |
| obsm | ||||
X_
|
The resulting PCA embedding. |
densematrix
|
float32
|
14249 × 50 |
| varm | ||||
pca_
|
The PCA loadings matrix. |
densematrix
|
float64
|
34617 × 50 |
| layers | ||||
counts
|
Raw counts |
sparsematrix
|
float32
|
14249 × 34617 |
normalized
|
Normalised expression values |
sparsematrix
|
float32
|
14249 × 34617 |
| uns | ||||
dataset_
|
Long description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
A unique identifier for the dataset. This is different from the obs.dataset_id field, which is the identifier for the dataset from which the cell data is derived.
|
atomic
|
str
|
1 |
dataset_
|
A human-readable name for the dataset. |
atomic
|
str
|
1 |
dataset_
|
The organism of the sample in the dataset. |
atomic
|
str
|
1 |
dataset_
|
Bibtex reference of the paper in which the dataset was published. |
atomic
|
str
|
1 |
dataset_
|
Short description of the dataset. |
atomic
|
str
|
1 |
dataset_
|
Link to the original source of the dataset. |
atomic
|
str
|
1 |
knn
|
Supplementary K nearest neighbors data. |
dict
|
3 | |
normalization_
|
Which normalization was used |
atomic
|
str
|
1 |
pca_
|
The PCA variance objects. |
dict
|
2 | |